
身近な機械学習
身近な機械学習
ここでは、機械学習が良く使われている例をご紹介します。
- ・スパムメールの検知
メールを受信すると、どれがスパムでどれがそうでないかを識別します。この問題のモデルがあれば、プログラムがスパムでない電子メールを受信ボックスに残し、スパム・メールをスパム・フォルダーへ移すということが可能になります。非常に有名な例の1つです。
- ・クレジットカード不正検知
ある顧客の1ヶ月のクレジットカード取引履歴から、それらの取引がその顧客によってなされたものか不正に利用されたかを識別します。これにより、クレジットカードの不正利用を早急に発見することが出来ます。
- ・数字認識
封筒の手書きの郵便番号を認識し、その手書き文字の数字を識別します。これにより、コンピューター・プログラムが手書きの郵便番号を読み取ることが出来るようになり、封筒を地域毎に仕分けることが可能になります。
機械学習の種類
機械学習は大きく分けて識別関数、識別モデル、生成モデルという3つのアプローチがあります。
◇識別関数:入力データを見て、特定のクラスに属するよう識別
—代表的な手法
- ・パーセプトロン
- ・サポートベクターマシン
◇識別モデル:入力データからクラス事後確率をモデル化して識別
—代表的な手法
- ・ロジスティック回帰
- ・ニューラルネットワーク
- ・決定木
◇生成モデル:入力データがどのような分布で生成されたものかをモデル化して識別
—代表的な手法
- ・ナイーブベイズ(単純ベイズ)分類器
- ・その他ベイジアン全体
線形識別器
ここでは、識別関数について説明します。さて識別するとはどういうことでしょうか。以下、簡単のため、2クラスの識別問題について考えていきます。
スパムメール検知を例にとします。まず、図で考えてみましょう。以下の図1をご覧ください。
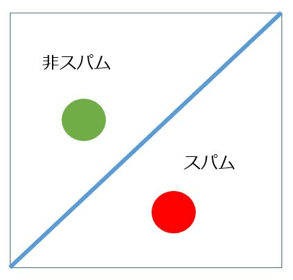
スパムではないメールを代表するプロトタイプを緑の点とし、スパムメールを代表するプロトタイプを赤の点とします。
両プロトタイプから等距離に引かれた直線を描きました。この直線は各プロトタイプから等距離にあるため、新しいメールを受信した際に、その属性がこの線より緑の点に近ければ“スパムでないメール”、赤の点に近ければ“スパムメール”だと考えること出来ます。
このように、入力データを各クラスに識別するような直線を超平面(あるいは決定境界や識別面)といいます。
つまり、識別する=超平面を求めることです。そして、超平面を求めるとは、正しいプロトタイプを適切に設定するということでもあります。
なぜなら、ここでいう超平面とは各プロトタイプから等距離に位置するものだからです。
また、このように超平面で完全にクラスを分離出来る場合を「線形分離可能である」といいます。



